

Машинное обучение
Привет, коллеги! Сегодня мы с вами отправимся в увлекательное путешествие по миру машинного обучения (МО). Если вы когда-либо задумывались, как Netflix знает, что вам понравится очередной фильм, или как ваш смартфон распознает ваше лицо, то вы на правильном пути. Давайте разберемся, как программирование и данные могут создавать настоящие чудеса.
Данные — это новое золото
Начнем с самого важного: данных. В современном мире данные — это не просто цифры или текст, это настоящее золото! Представьте себе, что вы находитесь в огромном океане информации. Каждый байт данных может стать ключом к пониманию сложных процессов. Но помните, что качество данных имеет огромное значение. Грязные или неполные данные могут превратить ваш шедевр в настоящую катастрофу.

Обучение — это искусство
Теперь, когда у нас есть данные, пора их обучить. Тут начинается настоящее волшебство! Мы можем использовать разные подходы:
- Обучение с учителем: представьте, что у вас есть учитель, который подсказывает вам правильные ответы. Это когда у нас есть метки, и мы можем учить модель на примерах.
- Обучение без учителя: здесь мы уже как детективы, ищущие скрытые паттерны в данных без подсказок.
- Обучение с подкреплением: это как тренировка собаки, где модель получает награды за правильные действия и штрафы за ошибки.
Типы данных: Разнообразие — ключ к успеху
Давайте поговорим о типах данных. Мы сталкиваемся с числовыми и категориальными данными. Числовые данные — это ваши любимые метрики, такие как возраст или доход. А категориальные данные — это более «человеческие» вещи, например, цвет автомобиля. Но не забывайте про неструктурированные данные: текстовые отзывы, изображения и видео. Они требуют особого подхода и могут стать настоящим вызовом!

Этапы машинного обучения: Пошаговое руководство
Теперь давайте пройдемся по этапам создания модели. Это как готовка вашего любимого блюда: нужно следовать рецепту!
- Сбор данных: Начнем с поиска ингредиентов. Где взять данные? API, базы данных или веб-скрейпинг — выбирайте любой способ!
- Предобработка данных: Прежде чем бросаться в обучение, очистите свои данные. Удалите пропуски и нормализуйте значения. Это как мыть овощи перед готовкой!
- Разделение данных: Не забудьте разделить данные на обучающую и тестовую выборки. Это поможет вам проверить, насколько хорошо ваша модель усвоила материал.
- Выбор алгоритма: В зависимости от задачи выбирайте алгоритм. Линейная регрессия для предсказаний? Деревья решений для классификации? Или может быть нейронные сети для сложных задач?
- Обучение модели: Запускайте алгоритм на обучающих данных и наблюдайте за процессом. Это как тренировка спортсмена!
- Оценка модели: Используйте тестовые данные для проверки производительности. Метрики вроде точности или F1-меры помогут вам понять, насколько ваша модель хороша.
- Оптимизация модели: Поиграйте с гиперпараметрами и посмотрите, как это повлияет на результаты. Это как настройка вашего кода для повышения производительности.
- Внедрение модели: Когда модель готова, интегрируйте её в приложение или сервис. Ваши пользователи будут благодарны!
Алгоритмы машинного обучения: Инструменты для творчества
Теперь давайте взглянем на инструменты, которые у нас есть в арсенале:
- Линейная регрессия: Простая и эффективная для предсказания числовых значений. Она работает по принципу «наилучшей прямой линии».
- Логистическая регрессия: Идеальна для бинарной классификации. Она использует сигмоидальную функцию для превращения выходного значения в вероятность.
- Деревья решений: Модели, которые принимают решения на основе вопросов о признаках. Они интуитивно понятны и легко визуализируются.
- Методы ансамблей: Например, Random Forest и Gradient Boosting объединяют несколько моделей для повышения точности.
- Нейронные сети: Мощные инструменты для работы с неструктурированными данными. Они состоят из слоев узлов (нейронов), которые обрабатывают информацию.
- Кластеризация: Алгоритмы вроде k-средних помогают группировать данные по схожести без предварительных меток.
Обучение модели: Как это работает?
Обучение модели — это процесс, похожий на написание кода:
- Инициализация: Установите начальные параметры модели.
- Обучение на данных: Запускайте алгоритм на обучающей выборке и смотрите, как модель учится.
- Валидация: Проверьте модель на валидационной выборке, чтобы избежать переобучения.
- Тестирование: Оцените производительность на тестовых данных — вот тут-то и проявляется вся ваша работа!
- Настройка гиперпараметров: Оптимизируйте параметры модели для достижения лучших результатов.

Инструменты и библиотеки: Ваши верные помощники
Теперь о том, какие инструменты помогут вам в этом путешествии:
- Python: Король среди языков программирования для МО.
- NumPy: Библиотека для работы с многомерными массивами — основа всего!
- Pandas: Ваш лучший друг для обработки и анализа данных.
- Scikit-learn: Библиотека с множеством алгоритмов и инструментов для предобработки данных.
- TensorFlow и Keras: Для тех, кто хочет погрузиться в мир глубокого обучения.
- PyTorch: Отличный инструмент для исследователей и разработчиков нейронных сетей.
- Matplotlib и Seaborn: Для визуализации ваших данных и результатов моделей.
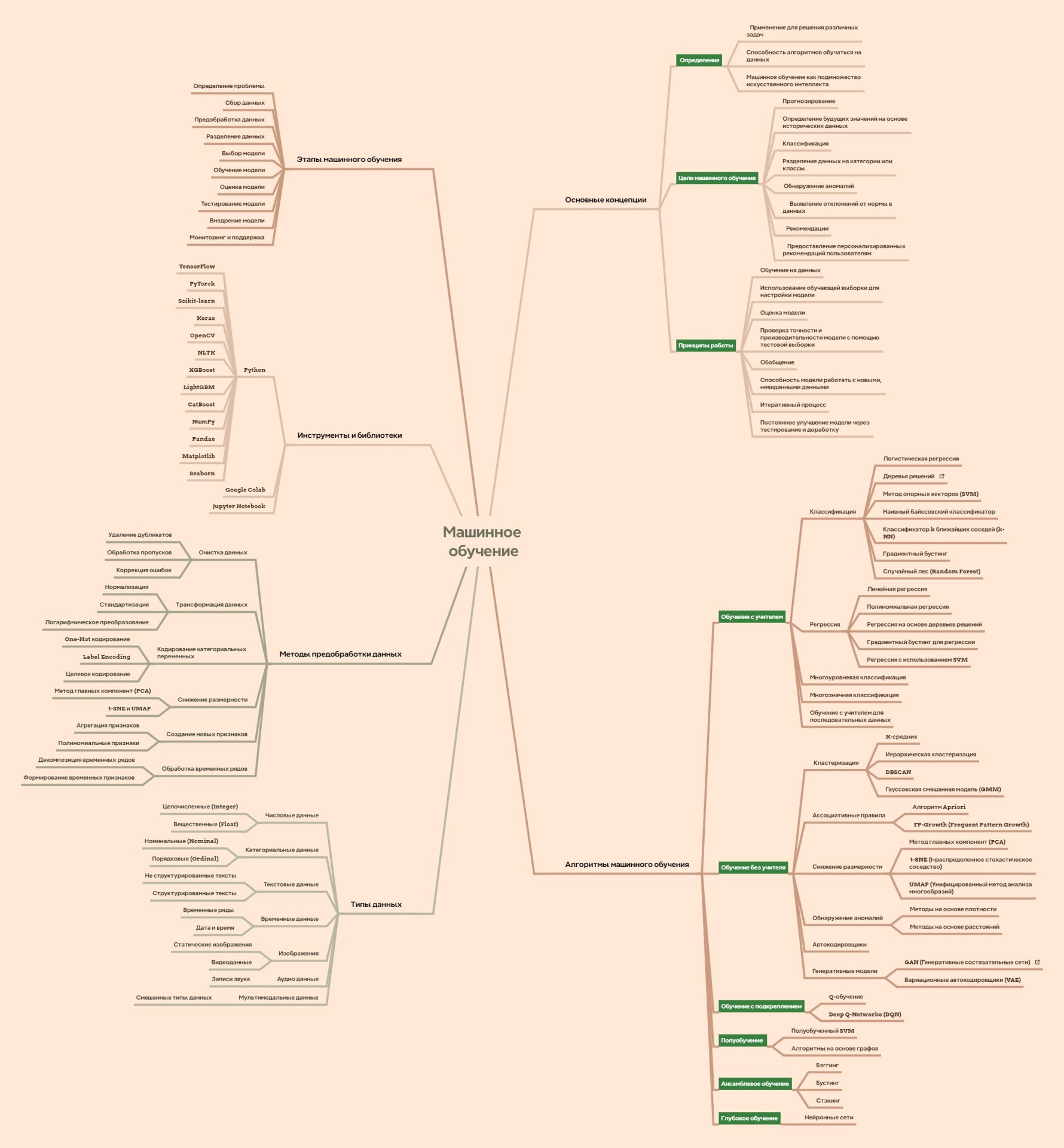
Примечание Фрукта: Предварительная карта мыслей по машинному обучения, она же - список всех тем для сайта. Постепенно будет перерабатываться, чтобы сложилось полное понимание предмета.
Заключение: Ваш следующий шаг
Машинное обучение — это не просто набор алгоритмов; это целая экосистема возможностей для решения реальных задач с помощью данных. Понимание основ МО откроет перед вами новые горизонты в программировании и аналитике. Надеюсь, эта лекция вдохновила вас погрузиться глубже в этот увлекательный мир! Так что вперед — к новым свершениям!









