

Библиотека Sklearn

Привет! Давай погрузимся в мир scikit-learn, одного из самых популярных и мощных инструментов для машинного обучения на Python. Это библиотека, которая позволяет легко и быстро реализовать различные алгоритмы машинного обучения и анализа данных. В этой статье мы рассмотрим, что такое scikit-learn, его основные компоненты, как его использовать, а также некоторые нюансы и примеры.
Сайт библиотеки с описанием функций и методов.

Что такое scikit-learn?
Scikit-learn — это библиотека для машинного обучения, построенная на основе других библиотек Python, таких как NumPy, SciPy и matplotlib. Она предоставляет простой и интуитивно понятный интерфейс для реализации алгоритмов машинного обучения, а также включает в себя инструменты для предобработки данных, оценки моделей и визуализации.
Основные компоненты scikit-learn
Scikit-learn состоит из нескольких ключевых компонентов:
- Алгоритмы машинного обучения: включает классификацию, регрессию, кластеризацию и уменьшение размерности.
- Предобработка данных: методы нормализации, стандартизации и обработки пропусков.
- Оценка модели: инструменты для оценки качества моделей, такие как перекрестная проверка (cross-validation).
- Визуализация: возможность визуализировать результаты работы моделей.
Установка scikit-learn
Чтобы установить scikit-learn, достаточно использовать pip:
pip install scikit-learnОсновные алгоритмы
Scikit-learn поддерживает множество алгоритмов машинного обучения. Вот несколько из них:
- Классификация: Logistic Regression, Decision Trees, Random Forests, Support Vector Machines (SVM).
- Регрессия: Linear Regression, Ridge Regression, Lasso Regression.
- Кластеризация: K-Means, DBSCAN, Hierarchical Clustering.
- Уменьшение размерности: PCA (Principal Component Analysis), t-SNE.
Предобработка данных
Перед тем как применять алгоритмы машинного обучения, важно правильно подготовить данные. Scikit-learn предлагает множество инструментов для предобработки данных:
- Нормализация: Приведение данных к одному масштабу. Например, MinMaxScaler преобразует данные так, чтобы они находились в диапазоне от 0 до 1.
- Стандартизация: Преобразование данных так, чтобы они имели среднее значение 0 и стандартное отклонение 1. Это достигается с помощью StandardScaler.
- Обработка пропусков: Заполнение пропусков средними значениями или медианами с помощью SimpleImputer.
Оценка моделей
Оценка качества моделей — важный шаг в процессе машинного обучения. В scikit-learn есть несколько методов для оценки моделей:
- Перекрестная проверка (cross-validation): позволяет оценить модель на различных подвыборках данных. Например, с помощью функции crossvalscore можно получить оценку модели на k фолдах.
- Метрики оценки: такие как точность (accuracy), полнота (recall), F1-score и другие. Эти метрики помогают понять, насколько хорошо модель справляется с задачей.
Преимущества и недостатки scikit-learn
Как и у любого инструмента, у scikit-learn есть свои плюсы и минусы:
Преимущества:
- Простота использования: Интуитивно понятный интерфейс и документация делают библиотеку доступной для новичков.
- Широкий выбор алгоритмов: Поддержка множества алгоритмов машинного обучения.
- Сообщество: Большое сообщество пользователей и разработчиков обеспечивает постоянное обновление и поддержку библиотеки.
Недостатки:
- Ограниченная работа с большими данными: Для работы с очень большими наборами данных могут потребоваться другие инструменты (например, Dask).
- Отсутствие поддержки глубокого обучения: Для задач глубокого обучения лучше использовать TensorFlow или PyTorch.
Заключение
Scikit-learn — это мощный инструмент для машинного обучения, который предоставляет широкий спектр возможностей для анализа данных и построения моделей. Его простота использования и богатый функционал делают его отличным выбором как для новичков, так и для опытных специалистов. Надеюсь, эта статья помогла тебе лучше понять scikit-learn и его возможности!
Пример на Python: Классификация цветков ириса с использованием K-Nearest Neighbors (KNN)
pip install numpy pandas scikit-learn
# Импортируем необходимые библиотеки
import numpy as np
import pandas as pd
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
# Загружаем набор данных ириса
iris = datasets.load_iris()
X = iris.data # Признаки (длина и ширина чашелистиков и лепестков)
y = iris.target # Целевая переменная (вид ириса)
# Разделяем данные на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Стандартизируем данные
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# Создаем модель KNN
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
# Делаем предсказания на тестовых данных
y_pred = model.predict(X_test)
# Оцениваем модель
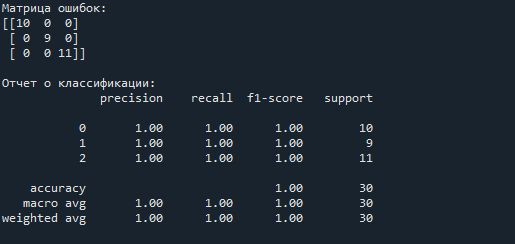
print("Матрица ошибок:")
print(confusion_matrix(y_test, y_pred))
print("\nОтчет о классификации:")
print(classification_report(y_test, y_pred))
В этом примере мы сначала загружаем данные о цветках ириса, затем разделяем их на обучающую и тестовую выборки. После этого стандартизируем данные и создаем модель KNN. Наконец, мы делаем предсказания и оцениваем качество модели с помощью матрицы ошибок и отчета о классификации.
Пример: Линейная регрессия для предсказания стоимости домов
# Импортируем необходимые библиотеки
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# Генерируем искусственные данные
np.random.seed(0)
X = 2 * np.random.rand(100, 1) # Площадь (в тысячах квадратных метров)
y = 4 + 3 * X + np.random.randn(100, 1) # Стоимость (в тысячах долларов)
# Разделяем данные на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Создаем модель линейной регрессии
model = LinearRegression()
model.fit(X_train, y_train)
# Делаем предсказания на тестовых данных
y_pred = model.predict(X_test)
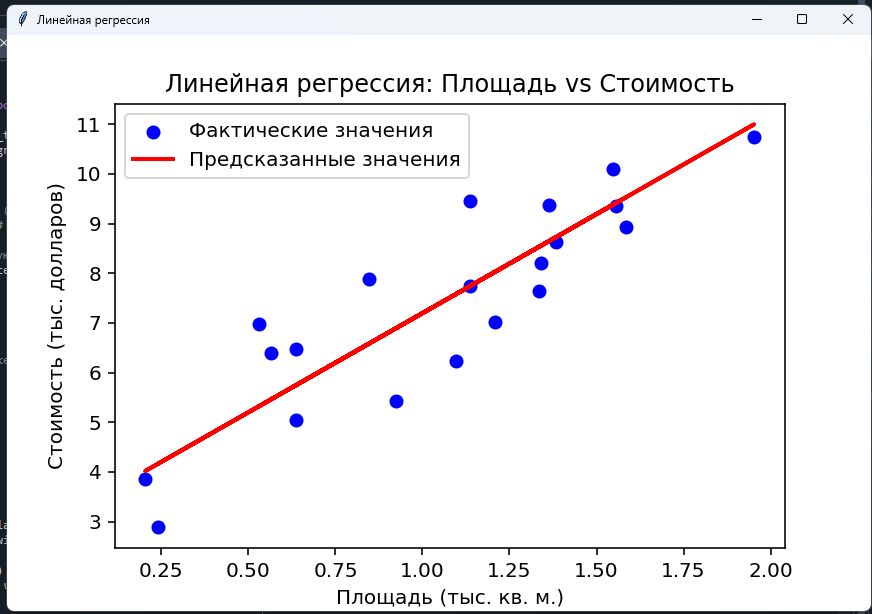
# Визуализируем результаты
plt.scatter(X_test, y_test, color='blue', label='Фактические значения')
plt.plot(X_test, y_pred, color='red', linewidth=2, label='Предсказанные значения')
plt.xlabel('Площадь (тыс. кв. м.)')
plt.ylabel('Стоимость (тыс. долларов)')
plt.title('Линейная регрессия: Площадь vs Стоимость')
plt.legend()
plt.show()
# Выводим коэффициенты модели
print(f'Коэффициент (наклон): {model.coef_[0][0]}')
print(f'Свободный член (пересечение): {model.intercept_[0]}')








