

Гиперпараметры

Давай поговорим о гиперпараметрах! Если ты когда-нибудь чувствовал себя, как будто ты в каком-то кулинарном шоу, где нужно угадать, сколько соли добавить в суп, то ты на правильном пути. Гиперпараметры — это те загадочные настройки, которые помогают твоей модели машинного обучения стать настоящим шеф-поваром, а не просто поваренком. Итак, давай раскроем эту тему с юмором и примерами!
Что такое гиперпараметры?
Гиперпараметры — это параметры, которые устанавливаются до начала обучения модели. Они не обучаются на данных, как обычные параметры. Это как выбор ингредиентов для твоего блюда: ты решаешь, что использовать, прежде чем начать готовить. Например, в алгоритме случайного леса у тебя есть такие гиперпараметры, как количество деревьев (nestimators) и максимальная глубина дерева (maxdepth).
Типы гиперпараметров
Существует несколько типов гиперпараметров, и вот некоторые из них:
- Структурные гиперпараметры: Определяют архитектуру модели. Например, количество слоев в нейронной сети.
- Гиперпараметры обучения: Определяют процесс обучения. Например, скорость обучения (learning rate).
- Регуляризационные гиперпараметры: Помогают предотвратить переобучение. Например, коэффициент L2-регуляризации.
Пример на Python
Давай используем датасет "Iris", который является классическим примером для задач классификации. Мы будем использовать RandomForestClassifier и визуализировать результаты с помощью библиотеки matplotlib и seaborn.
Вот пример кода, который включает в себя обучение модели, визуализацию данных и результатов классификации:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
from sklearn.datasets import load_iris
# Загружаем датасет Iris
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
# Преобразуем в DataFrame для удобства
df = pd.DataFrame(X, columns=feature_names)
df['species'] = y
# Визуализация данных
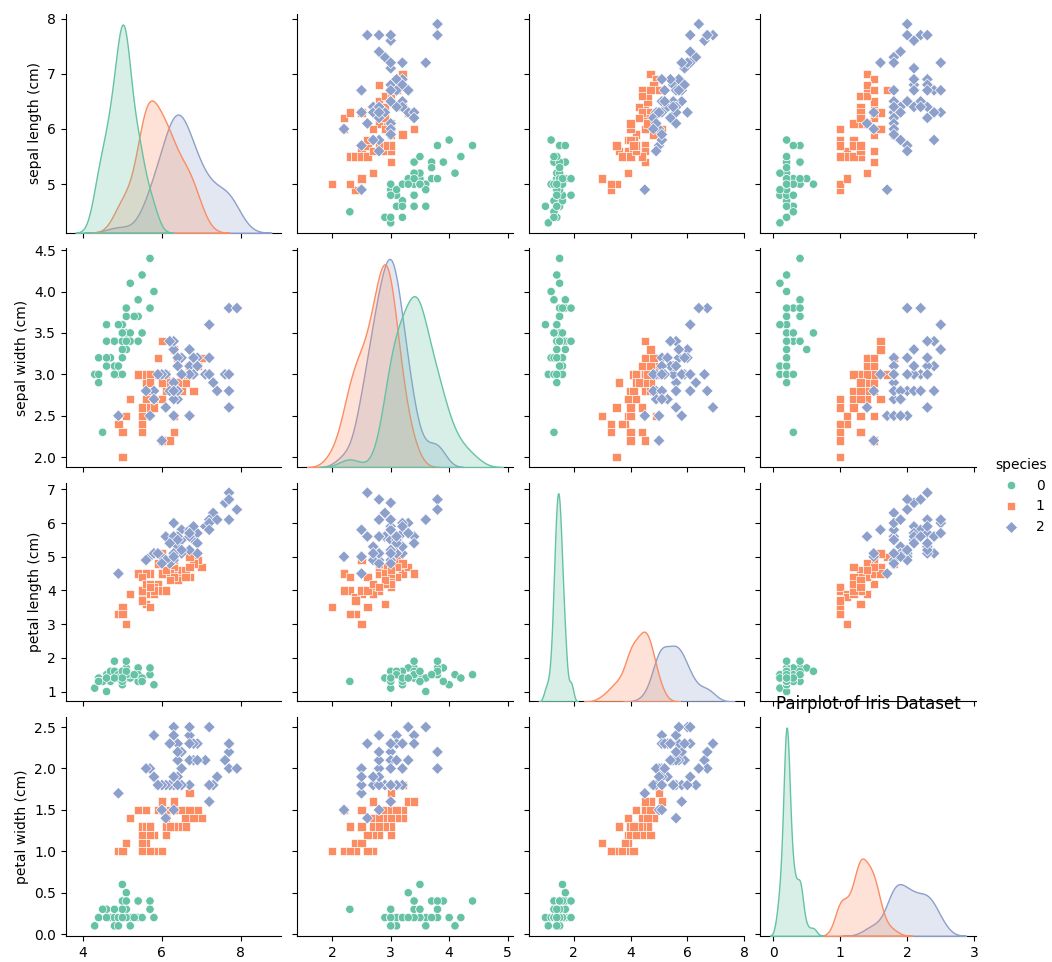
sns.pairplot(df, hue='species', palette='Set2', markers=["o", "s", "D"])
plt.title("Pairplot of Iris Dataset")
plt.show()
# Разделяем данные на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Определяем модель
model = RandomForestClassifier()
# Задаем гиперпараметры для подбора
param_grid = {
'n_estimators': [50, 100, 150],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10],
'max_features': ['auto', 'sqrt']
}
# Настраиваем GridSearchCV для подбора гиперпараметров
grid_search = GridSearchCV(estimator=model, param_grid=param_grid,
scoring='accuracy', cv=5, n_jobs=-1)
# Обучаем модель с использованием GridSearchCV
grid_search.fit(X_train, y_train)
# Получаем лучшие параметры
best_params = grid_search.best_params_
print("Лучшие гиперпараметры:", best_params)
# Оцениваем модель на тестовой выборке
best_model = grid_search.best_estimator_
y_pred = best_model.predict(X_test)
# Выводим результаты
print("Точность на тестовой выборке:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
# Визуализация матрицы ошибок
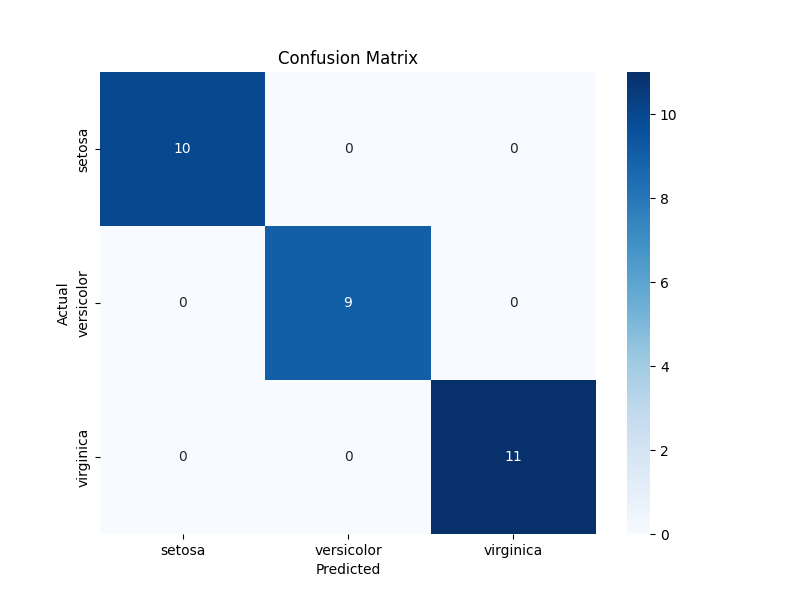
conf_matrix = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues',
xticklabels=target_names, yticklabels=target_names)
plt.ylabel('Actual')
plt.xlabel('Predicted')
plt.title('Confusion Matrix')
plt.show()
Объяснение кода:
1. Загрузка данных: Используем load_iris() для загрузки датасета Iris.
2. Преобразование в DataFrame: Данные преобразуются в DataFrame для удобства визуализации.
3. Визуализация данных: Используем seaborn для построения парного графика (pairplot), который показывает распределение признаков по категориям.
4. Разделение данных: Данные делятся на обучающую и тестовую выборки.
5. Определение модели: Используем RandomForestClassifier.
6. Подбор гиперпараметров: Используем GridSearchCV для поиска лучших гиперпараметров.
7. Оценка модели: Оцениваем модель на тестовой выборке и выводим точность и отчет по классификации.
8. Визуализация матрицы ошибок: Строим тепловую карту (heatmap) для визуализации матрицы ошибок.
Советы по настройке гиперпараметров
- Не перебарщивай: Слишком много гиперпараметров могут усложнить жизнь. Сосредоточься на самых важных.
- Используй кросс-валидацию: Это поможет избежать переобучения и даст более надежные результаты.
- Не забывай про время: Настройка гиперпараметров может занять много времени. Убедись, что у тебя достаточно ресурсов.
Интересные факты о гиперпараметрах
- Знаешь ли ты, что многие известные модели были настроены с помощью простых методов? Например, первые версии нейронных сетей использовали только два-три гиперпараметра!
- В мире машинного обучения существует даже целый термин — "гиперпараметрическая оптимизация". Это звучит как название нового фильма о супергероях!
Так что в следующий раз, когда ты будешь настраивать свою модель, помни: гиперпараметры — это твои лучшие друзья на кухне машинного обучения. Не бойся экспериментировать и находить идеальные сочетания!









