

Стратификация

Стратификация в машинном обучении
Давайте разберемся, что такое стратификация и как она может спасти вашу модель от неудачи. Стратификация — это как разделение пирога на куски: каждый кусок должен быть равномерным, чтобы все гости были довольны. В мире машинного обучения это означает, что мы должны убедиться, что все классы в наших данных представлены в обучающей и тестовой выборках.
Почему стратификация важна?
Представьте, что вы разрабатываете модель для предсказания того, купит ли человек новый смартфон. Если в вашем наборе данных 90% людей не покупают смартфоны и только 10% — покупают, ваша модель может научиться игнорировать покупателей, ведь ей будет проще предсказать «не купит». Это как если бы вы всегда ставили на то, что ваш друг не придет на вечеринку — в итоге вы можете пропустить кучу веселья!
Как работает стратификация?
Стратификация делит данные на подгруппы (страты) по какому-либо критерию, например, по классу. Это помогает избежать проблем с несбалансированными данными. Давайте посмотрим, как это можно сделать на Python с помощью библиотеки scikit-learn.
Пример: Стратификация в действии
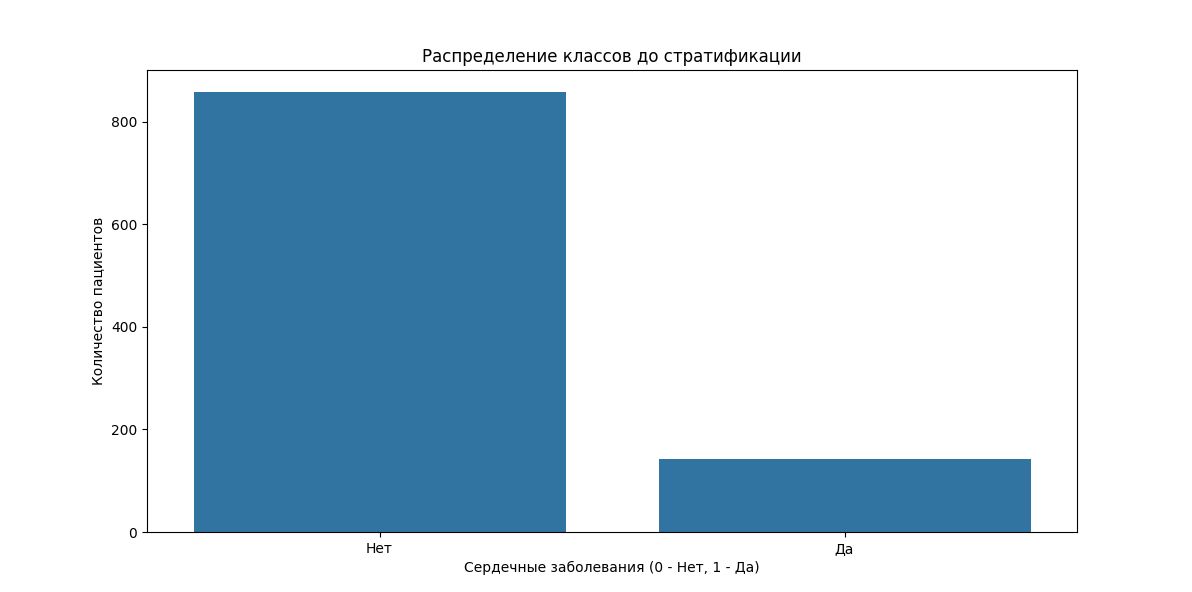
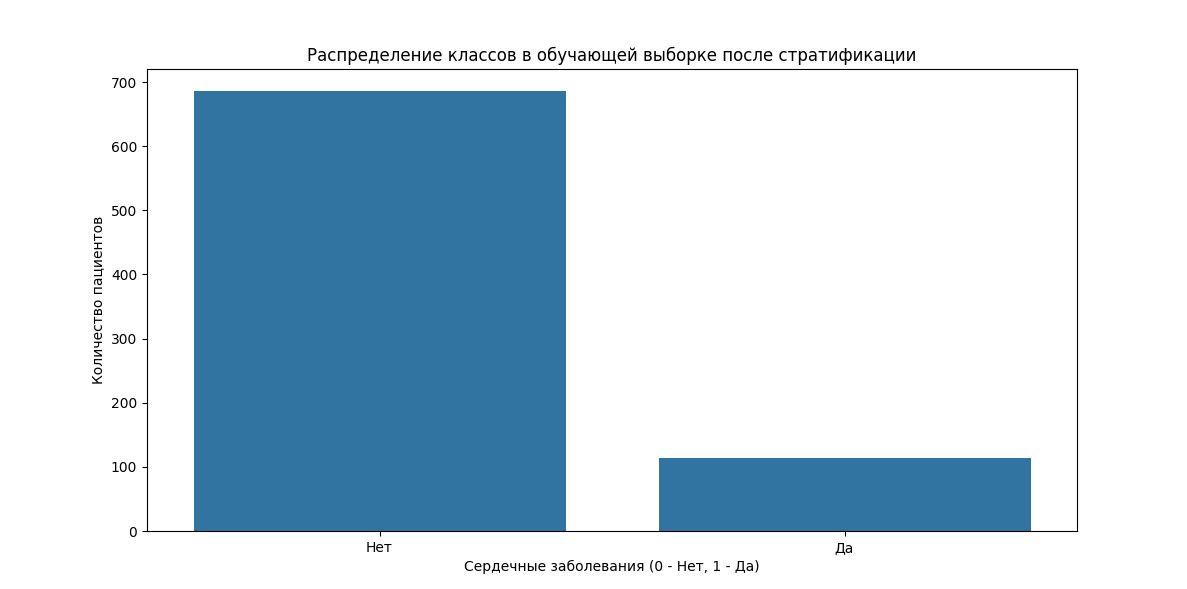
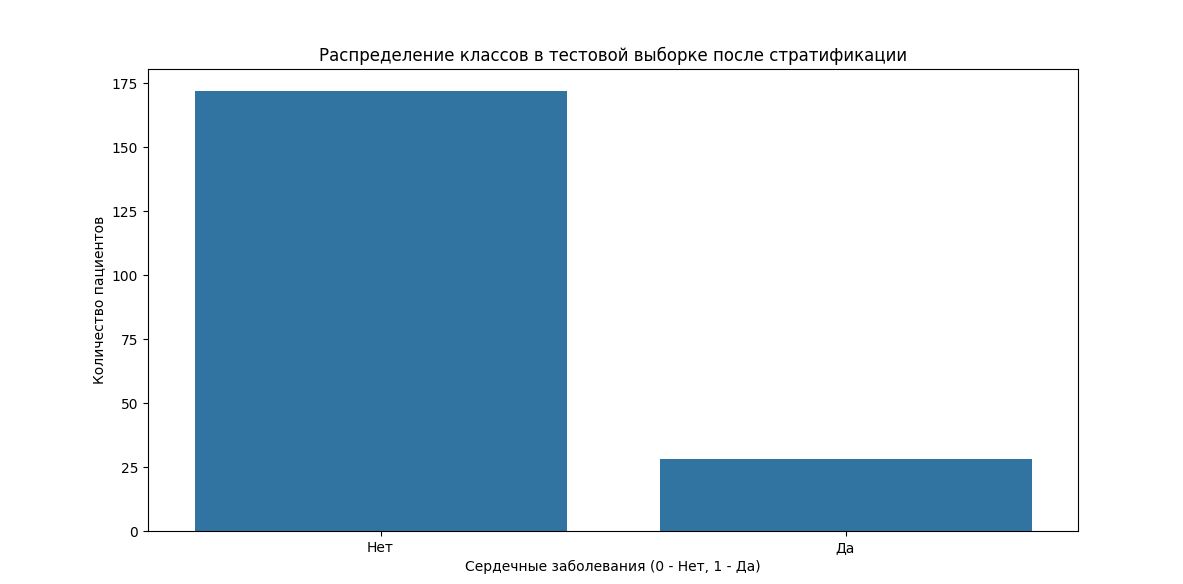
В этом примере мы создадим набор данных о пациентах с различными заболеваниями и визуализируем распределение классов до и после стратификации.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
# Устанавливаем семя для воспроизводимости
np.random.seed(42)
# Создаем пример данных
data_size = 1000
data = {
'Age': np.random.randint(18, 70, size=data_size),
'Cholesterol': np.random.choice(['Normal', 'High'], size=data_size, p=[0.7, 0.3]),
'Heart_Disease': np.random.choice([0, 1], size=data_size, p=[0.85, 0.15]) # 15% с сердечными заболеваниями
}
df = pd.DataFrame(data)
# Визуализируем исходное распределение классов
plt.figure(figsize=(12, 6))
sns.countplot(x='Heart_Disease', data=df)
plt.title('Распределение классов до стратификации')
plt.xlabel('Сердечные заболевания (0 - Нет, 1 - Да)')
plt.ylabel('Количество пациентов')
plt.xticks([0, 1], ['Нет', 'Да'])
plt.show()
# Стратифицируем данные по классу Heart_Disease
train_df, test_df = train_test_split(df, test_size=0.2, stratify=df['Heart_Disease'], random_state=42)
# Визуализируем распределение классов после стратификации
plt.figure(figsize=(12, 6))
sns.countplot(x='Heart_Disease', data=train_df)
plt.title('Распределение классов в обучающей выборке после стратификации')
plt.xlabel('Сердечные заболевания (0 - Нет, 1 - Да)')
plt.ylabel('Количество пациентов')
plt.xticks([0, 1], ['Нет', 'Да'])
plt.show()
plt.figure(figsize=(12, 6))
sns.countplot(x='Heart_Disease', data=test_df)
plt.title('Распределение классов в тестовой выборке после стратификации')
plt.xlabel('Сердечные заболевания (0 - Нет, 1 - Да)')
plt.ylabel('Количество пациентов')
plt.xticks([0, 1], ['Нет', 'Да'])
plt.show()Описание кода:
1. Генерация данных:
• Мы создаем набор данных с 1000 пациентами, где каждый пациент имеет возраст, уровень холестерина и наличие сердечных заболеваний.
• Уровень холестерина имеет два класса: "Normal" и "High", а наличие сердечных заболеваний представлено бинарно (0 - нет, 1 - да) с дисбалансом (85% без заболеваний и 15% с заболеваниями).
2. Визуализация:
• Мы используем countplot из библиотеки seaborn, чтобы визуализировать распределение классов до и после стратификации.
• Первый график показывает распределение классов в исходном наборе данных.
• Второй и третий графики показывают распределение классов в обучающей и тестовой выборках соответственно после стратификации.
Запуск кода:
Чтобы запустить этот код, убедитесь, что у вас установлены необходимые библиотеки:
Интересные факты о стратификации
- Стратификация может значительно улучшить качество модели — иногда на 10-20%! Не верите? Проверьте сами!
- Некоторые исследователи считают, что стратификация — это как добавление специй в блюдо: без неё всё будет плоским и неинтересным.
- Стратификация особенно важна в задачах классификации с несколькими классами. Чем больше классов, тем больше вероятность получить несбалансированные данные.
Заключение
Надеюсь, вы поняли, что стратификация — это не просто модное слово из мира машинного обучения. Это мощный инструмент, который поможет вам создавать более точные и надежные модели. Так что в следующий раз, когда вы будете работать с данными, не забудьте про стратификацию — это как добавление щепотки соли в ваше любимое блюдо: сделает его намного вкуснее!









